파이썬 웹 스크래핑으로 웹 데이터를 자동 수집하는 방법: BeautifulSoup 파이썬부터 크롤링 자동화까지
파이썬 웹 스크래핑은 requests로 HTML을 가져오고 BeautifulSoup로 필요한 데이터만 추출해 자동 수집하는 방식입니다. 정적 페이지부터 시작해 크롤링 자동화까지 자연스럽게 확장할 수 있습니다.
1. 파이썬 웹 스크래핑의 개념과 검색 의도
파이썬 웹 스크래핑은 웹페이지에서 필요한 정보만 골라 자동으로 모으는 방법입니다. 사용자는 보통 반복적인 복사·붙여넣기를 줄이고, 원하는 데이터를 정리된 형태로 빠르게 얻고 싶어 이 주제를 찾습니다.
이 키워드는 단순한 개념 설명보다 *실무 적용*과 *자동화*에 대한 관심이 함께 있는 검색어입니다. 그래서 이 글에서는 기본 원리부터 실제 수집 흐름까지 한 번에 연결해 봅니다.
핵심은 화면에 보이는 모습이 아니라, 실제로 내려받은 HTML 구조를 읽는 것입니다. 이 차이를 이해하면 BeautifulSoup파이썬과 크롤링 자동화를 훨씬 쉽게 연결할 수 있습니다.
2. BeautifulSoup 파이썬과 requests를 함께 쓰는 이유
requests는 웹페이지 주소에 접속해 HTML을 가져오는 역할을 하고, Beautiful Soup는 그 HTML을 읽기 쉽게 바꿔 필요한 태그를 찾게 해 줍니다. 즉, requests는 *가져오기*, BeautifulSoup는 *읽고 찾기*입니다.
이 조합이 강력한 이유는 정적 페이지에서 매우 효율적으로 동작하기 때문입니다. 제목, 문단, 목록, 링크처럼 구조가 단순한 데이터는 이 방식으로 빠르게 추출할 수 있습니다.
- requests: HTML을 가져오는 도구
- BeautifulSoup: HTML에서 필요한 요소를 찾는 도구
- 정적 페이지: HTML 안에 데이터가 바로 있는 페이지
- 동적 페이지: 화면에는 보이지만 HTML에 데이터가 없을 수 있는 페이지
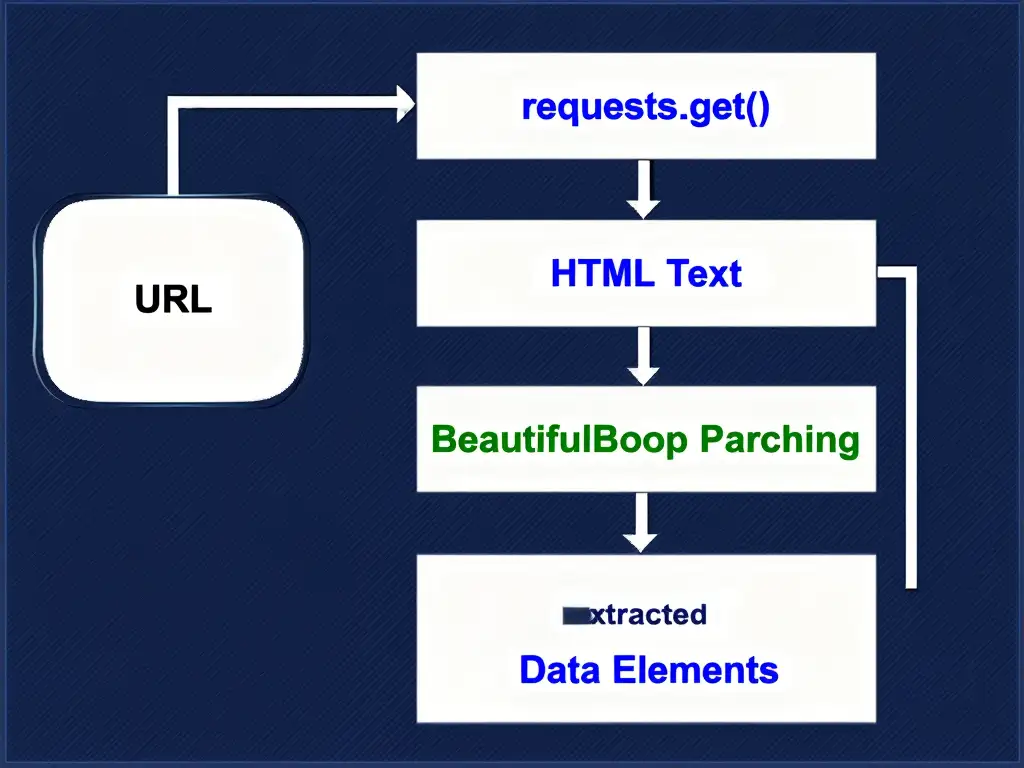
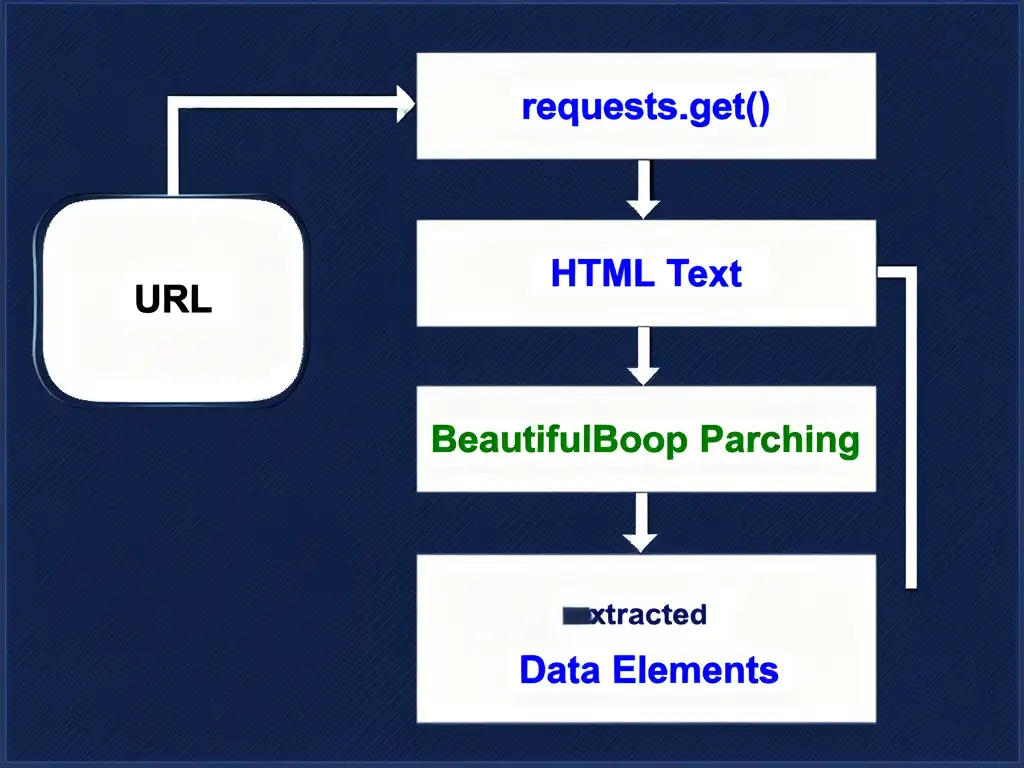
기본 흐름은 단순합니다. 먼저 URL에 requests.get()으로 접속하고, response.text로 HTML을 받은 뒤, BeautifulSoup(response.text, ‘html.parser’)로 파싱합니다. 이후 find, select, text를 사용해 원하는 내용을 꺼냅니다.

3. 실제 웹페이지에서 데이터 추출하는 절차
실전에서는 먼저 대상 URL을 정하고, requests로 HTML을 가져옵니다. 그다음 개발자 도구로 원하는 정보가 들어 있는 태그와 속성을 확인한 뒤, BeautifulSoup로 추출합니다. 마지막으로 결과를 출력하거나 저장하면 됩니다.
이때 중요한 것은 *어떤 태그에 데이터가 들어 있는지*를 정확히 파악하는 일입니다. 같은 페이지라도 제목, 본문, 목록, 링크는 서로 다른 태그 구조를 가질 수 있습니다.
| 단계 | 할 일 | 핵심 도구 |
|---|---|---|
| 1 | 대상 URL 정하기 | 브라우저 |
| 2 | HTML 가져오기 | requests |
| 3 | 태그 구조 확인 | 개발자 도구 |
| 4 | 데이터 추출 | BeautifulSoup |
| 5 | 정리 및 저장 | 리스트, 데이터프레임 |
예를 들어 위키피디아처럼 구조가 비교적 단순한 페이지에서는 h1과 p 태그를 찾아 제목과 설명을 쉽게 뽑을 수 있습니다. 뉴스 목록처럼 항목이 반복되는 페이지라면 select를 써서 여러 개의 제목을 한 번에 가져오는 방식이 잘 맞습니다.
4. 크롤링 자동화로 확장하는 방법
한 번만 데이터를 가져오는 것이 아니라 반복 수집으로 확장하면 크롤링 자동화가 됩니다. 핵심은 검색어를 변수로 두고 URL에 붙여서, 실행할 때마다 다른 결과를 가져오도록 만드는 것입니다.
예를 들면 base_url과 keyword를 합쳐 search_url을 만들 수 있습니다. 그러면 검색어만 바꿔도 결과가 달라지고, 여러 페이지를 반복문으로 돌리면 더 많은 데이터를 모을 수 있습니다. 이것이 파이썬 웹 자동화의 실용적인 형태입니다.
- 검색어를 변수로 만든다
- URL을 자동으로 조합한다
- 여러 페이지를 순회한다
- 결과를 리스트에 누적한다
- 파일이나 데이터프레임으로 저장한다
이 방식은 검색 결과 목록, 상품 목록, 게시글 목록처럼 반복 구조가 있는 페이지에 특히 유용합니다. 반복 작업을 줄이고 수집 범위를 넓히는 데 강점이 있습니다.

5. 실전 예시와 주의사항
첫 번째 예시는 위키피디아 문서입니다. 구조가 비교적 단순해서 h1과 p 태그를 찾는 연습에 좋고, 제목과 본문 일부를 뽑아보며 기본 감각을 익히기 좋습니다.
두 번째 예시는 뉴스 제목 수집입니다. select로 여러 개의 제목을 한 번에 가져오면 리스트 형태로 정리하기 쉽습니다. 이런 방식은 검색 결과 목록이나 게시글 목록처럼 항목이 반복되는 페이지에 잘 맞습니다.
| 예시 | 추출 대상 | 잘 맞는 기능 |
|---|---|---|
| 위키피디아 | 제목, 설명 | find, text |
| 뉴스 목록 | 기사 제목들 | select, text |
| 검색 결과 | 반복 항목 | 반복문, 누적 저장 |
모든 페이지가 BeautifulSoup만으로 해결되지는 않습니다. HTML 안에 실제 데이터가 없는 동적 페이지는 다른 도구가 필요할 수 있습니다. 그래서 먼저 정적 페이지인지 확인하는 습관이 중요합니다.
- 정적 페이지인지 먼저 본다
- HTML에 데이터가 실제로 있는지 확인한다
- User-Agent를 점검한다
- 너무 빠른 반복 요청은 피한다
- 사이트 정책을 확인한다
또한 requests의 기본 User-Agent는 python-requests로 잡힐 수 있어 일부 사이트에서는 요청이 막히거나 다른 응답을 받을 수 있습니다. 반복 요청은 서버에 부담을 줄 수 있으니 요청 간격도 함께 고려해야 합니다.

6. 초보자 체크리스트와 시작 순서
작업 전에는 대상 URL, 필요한 라이브러리, HTML 구조, 선택자 후보를 먼저 확인합니다. 추출 중에는 response 상태, 인코딩, 선택자 정확도, 빈 값 여부를 점검합니다.
저장 전에는 중복, 공백, 리스트화, CSV 또는 데이터프레임 변환 가능 여부를 확인합니다. 이 순서를 익히면 초보자도 실수를 줄이고 흐름을 안정적으로 잡을 수 있습니다.
| 구간 | 확인할 것 |
|---|---|
| 작업 전 | URL, 라이브러리, 구조, 선택자 |
| 추출 중 | 상태 코드, 인코딩, 값 존재 여부 |
| 저장 전 | 중복 제거, 공백 정리, 형식 변환 |
처음 실습할 때는 복잡한 사이트보다 구조가 단순한 페이지를 고르는 것이 좋습니다. 먼저 정적 페이지인지 확인하고, requests로 HTML을 가져온 뒤, BeautifulSoup로 태그를 찾고, 마지막으로 결과를 표나 파일로 정리하면 됩니다.
이 순서가 익숙해지면 검색어를 변수로 바꾸고, 페이지 수를 늘리고, 결과를 자동 저장하는 방식으로 자연스럽게 확장할 수 있습니다. 그렇게 하면 파이썬 웹 스크래핑은 단순한 연습이 아니라 반복 업무를 줄이는 실제 도구가 됩니다.
7. 자주 묻는 질문 (FAQ)
Q1. BeautifulSoup만으로 모든 웹사이트를 스크래핑할 수 있나요?
아니요. BeautifulSoup는 HTML 안에 데이터가 있는 정적 페이지에 특히 잘 맞습니다. 자바스크립트로 나중에 로드되는 동적 페이지는 다른 접근이 필요할 수 있습니다.
Q2. requests와 BeautifulSoup의 차이는 무엇인가요?
requests는 웹페이지의 HTML을 가져오는 역할이고, BeautifulSoup는 가져온 HTML을 파싱해 필요한 정보를 찾는 역할입니다. 둘은 함께 쓸 때 가장 자연스럽게 작동합니다.
Q3. 크롤링과 스크래핑은 같은 뜻인가요?
같지는 않습니다. 스크래핑은 한 페이지에서 필요한 데이터를 추출하는 작업이고, 크롤링은 여러 페이지를 링크를 따라가며 수집하는 작업입니다.
Q4. 초보자는 어떤 페이지부터 연습하면 좋나요?
구조가 단순한 정적 페이지부터 시작하는 것이 좋습니다. 위키피디아 같은 문서형 페이지나 반복 구조가 분명한 목록 페이지가 연습에 적합합니다.
Q5. 스크래핑할 때 가장 먼저 확인할 점은 무엇인가요?
먼저 HTML 안에 실제 데이터가 있는지 확인해야 합니다. 그다음 요청 상태, 선택자 정확도, 사이트 정책, 요청 간격을 함께 점검하면 안전하게 접근할 수 있습니다.